SDL TRADOS(トラドス)という翻訳支援ツールは、マニュアルや取扱説明書などの大量のボリュームを翻訳する際に非常に有効なツールとして広く翻訳業界では知れ渡っています。もっと言えばマニュアル翻訳では TRADOS(トラドス)を使用するのが常識です。
しかしながら、その SDL TRADOS(トラドス)の原理原則についてしっかりと理解しなければ、本当に使いこなせているとは言い切れません。そんな中、もっとも基礎的な原理である TRADOS(トラドス)の解析アルゴリズムについて解説いたします。
SDL TRADOS(トラドス)では旧バージョンとの比較・解析が可能です。つまり、「旧バージョンの原文と新バージョンの原文との間で、どの程度の改訂率があるのか」を数値(ワード数や文字数)で確認することができます。 ではこの TRADOS(トラドス)の解析アルゴリズムは具体的にどのように行われているのでしょうか。
例として以下のような翻訳・ローカライズケースを考えてみます。
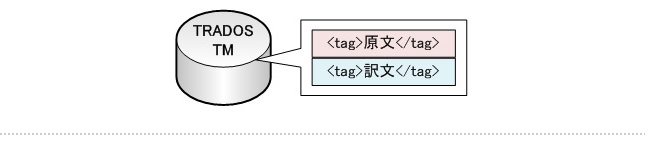
SDL TRADOS(トラドス)を使用して解析作業を行う場合、厳密には、Translation Memory 内のセグメント(文節)と実際の翻訳対象ファイルとの原文同士のマッチングによる解析なります。
TRADOS(トラドス)の Translation Memory 内は、旧バージョンの英語と日本語のペアになって格納されています。
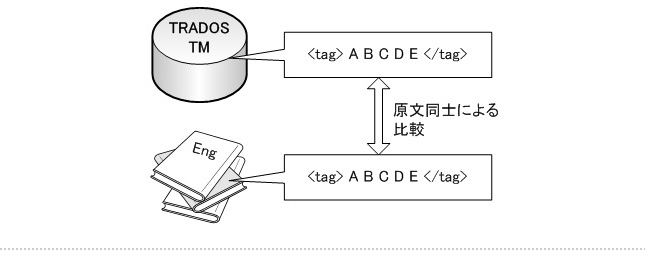
この Translation Memory 内の原文(この場合は英文)と、実際の翻訳対象ファイル(英文)とのマッチングが行われます。これが TRADOS(トラドス)の原文同士による比較です。
このように、TRADOS(トラドス)TM と翻訳対象である現行バージョンのFrameMaker(フレームメーカー)マニュアルとのマッチングにより「マッチ率」と呼ばれる数値が算出されます。この数値が今回のマニュアル翻訳のお見積書のベースとなります。まれに、原文同士の比較ではなく、訳文同士の比較(差分)だと勘違いしてしまう場合もありますが、訳文同士による比較アルゴリズムではありませんのでご注意ください。
TRADOS(トラドス)による解析結果では、旧バージョンとの比較結果が、数値になって現れます。解析結果にある CSV ファイルおよび Log ファイル中には以下の項目が含まれています。
解析表の意味は以下のようになっております。
※No Match は Full Rate と同じ意味です。
※実際の解析結果項目はより詳細に分かれています。あくまで説明のために省略しております。